Nathan Wailes - Blog - GitHub - LinkedIn - Patreon - Reddit - Stack Overflow - Twitter - YouTube
AWS / Amazon Web Services (Web development)
Table of contents
Child pages
Related Services
- Convox - They abstract away all of Amazon's services.
- This was a tip from Nathan at the Indie Hackers meetup.
AWS Services
Cloud9
- Amazon Docs - Working with Amazon Lightsail Instances in the AWS Cloud9 Integrated Development Environment (IDE)
- I used this tutorial to get Streamscan set up.
- I needed to install Python 2.7, I used the steps explained here.
Lightsail
- To get Filezilla working with Lightsail I followed the instructions I found here:
- When you "Open Connection", Choose SFTP
- Server is the Public IP for your instance (port will be 22)
- Username is indicated on the "Connect" tab of manage instance
- Choose the SSH Private Key for the instance (you can download the Default Key from the accounts page if you didn't create/upload your own)
- To install Apache I followed the instructions I found here: 2018.02.14 - Saowen - Deploying python Flask web app on Amazon Lightsail
- To create a virtualenv I followed the instructions I found here:
- sudo pip3 (or pip2) install virtualenv
- virtualenv venv
- source venv/bin/activate
- deactivate
- I created symlinks to the following things:
- ln -s /var/log/apache2/error.log error.log
- ln -s /var/www/<project_name> <project_name>
- ln -s /var/www/<project_name>/venv/bin/activate activate_venv
- To get the server to run in a virtualenv I followed some instructions I found here:
- Open up /etc/apache2/sites-available/<your_website>.conf
- Look for a line that says "WSGIDaemonProcess <name_of_the_app>"
- Change it to read "WSGIDaemonProcess <name_of_the_app> python-home=/path/to/the/venv"
Books / Courses / Tutorials
Books
Amazon Web Services for Dummies
- This book seems great; it's an overview of what AWS offers aimed at newbies.
Part I: Getting Started with AWS
Chapter 1: Amazon Web Services Philosophy and Design
Chapter 2: Understanding the AWS API
Chapter 3: Introducing the AWS Management Console
Part II: Diving into AWS Offerings
Chapter 4: Setting Up AWS Storage
Chapter 5: Stretching Out with Elastic Compute Cloud
Chapter 6: AWS Networking
Chapter 7: AWS Security
Chapter 8: Additional Core AWS Services
Part III: Using AWS
Chapter 9: AWS Platform Services
Chapter 10: AWS Management Services
Chapter 11: Managing AWS Costs
Chapter 12: Bringing It All Together: An AWS Application
Part IV: The Part of Tens
Chapter 13: Ten Reasons to Use Amazon Web Services
Chapter 14: Ten Design Principles for Cloud Applications
Courses
YouTube - Academind - AWS Basics
Account Security with IAM
- To control the security of our AWS account, we can search for "IAM" from the AWS dashboard.
- We're talking about giving permissions to certain people (e.g. other developers you're working with) or services.
- In the left-sidebar you'll see Groups, Users, Roles, and Policies.
- By default, new users have no permissions.
- He clicks Groups → Create New Group, chooses a Group Name of "admin", and then chooses the "AdministratorAccess" Policy.
- Why create an admin group? 1) New users won't have admin rights unless you grant them, and 2) users granted these rights will still not have access to some permissions, like billing permissions.
- Don't use your root account for non-billing work. Instead, create a user for yourself.
- He clicks Users → Add User, names the user after himself.
- He explains the two kinds of access types:
- AWS Management Console access just lets people log into the website.
- Programmatic access lets the user use the AWS API, CLI, SDK, and other tools.
- He adds permissions to the new user. He says the best practice is to add the user to a Group.
- When you finish creating the user, you're shown a particular link that users of your AWS instance(?) need to use to log in.
- He explains that another step for increasing security is to enable multi-factor authentication (MFA) for your account, and to set an option to prompt new users to also set up MFA.
- Another step for increasing security is to set up an IAM password policy to require users to create strong passwords.
- He looks at the "Policies" section and clicks on one, and shows that it's just JSON that defines the version of the policy and a series of rules for that policy.
- He explains that the Roles are used to grant permissions to AWS services to be able to access other AWS services.
UDemy - AWS Serverless APIs & Apps - A Complete Introduction
- UDemy - AWS Serverless APIs & Apps - A Complete Introduction
- the instructor is Max Schwarzmuller
- Q: Can I host a blog / forum / wiki if I use a serverless architecture?
Section 1: Getting Started
1. Introduction
- In this course I will explain what serverless computing means and how it works, and then dive into the AWS services necessary to do this.
- We will develop an API step-by-step as we go through the course.
- Prerequisites:
- You don't need to be a sysadmin.
- You should have a rough idea of what AWS is.
- You need a credit card to use AWS.
- You should know what APIs and SPAs are.
- It's a plus if you know JavaScript.
2. What is AWS?
- AWS stands for "Amazon Web Services".
- It offers a broad range of cloud computing services.
- You can rent their services to run your own applications on them.
- They have a "Free Tier" that lets you explore their offerings.
3. AWS - A Closer Look (Optional)
- This isn't a video, just a list of strongly-recommended links for people for whom AWS is "relatively or completely new".
- Videos
- Text
4. What is Serverless Development?
- The traditional method of hosting websites is to have a server that renders HTML and passes it to the user.
- In the serverless pattern, you decouple the frontend and backend, so that the backend is just an API.
- Problems that serverless computing solves:
- One issue with dealing with servers yourself is that you have to write a lot of infrastructure code for handling requests and setting up endpoints, which isn't your business logic.
- Another issue is that your servers are online even if they're not required (overprovisioning).
- Another issue is that you might not set up enough servers (underprovisioning).
- Another problem is that we need to keep the OS and software updated.
- With serverless computing there are still servers, but they are managed by Amazon. We just provide our code and it's executed on demand.
- There is only limited support for full-stack apps with a serverless architecture (where "full-stack" means the server is not merely an API but is actually passing HTML to the user).
5. Does AWS Cost Money?
- Yes, but there is a one-year free trial.
- He doesn't actually say how much to expect to pay if you don't have the free trial available.
6. AWS Signup & First Serverless API
- He walks through the sign-up process.
- He uses the "AWS Services" search box on the main console page to search for "api" and selects "API Gateway".
- He clicks "Get Started", and then "New API".
- In the UI for the new API, he clicks "Actions" and then "New Resource".
- He then clicks "Actions" and "Add Method" to add an HTTP method to the resource he just created.
- For the Integration Type he selects "Mock".
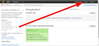
- In the new Method Execution screen (
 ) he clicks "Integration Response", then he clicks the triangular dropdown icon (
) he clicks "Integration Response", then he clicks the triangular dropdown icon ( ), then "Body Mapping Templates".
), then "Body Mapping Templates". - He then clicks "application/json" and puts in a sample JSON response: { "message": "This is working!" }
- He then goes to Actions → Deploy API, selects the "Deployment stage" dropdown and selects [New Stage], and names it "dev", and clicks "Save".
- The UI now shows a URL, which is the URL we can use for our API. He copies it, appends the resource URL he created (in his case, it was "first-api-test", and when he visits that URL, it shows the JSON response.
7. Why AWS?
- Other options are Microsoft Azure and Google Cloud Platform.
- He prefers AWS for the following reasons:
- They're the market leader.
- They have aggressive, constantly-decreasing prices.
- They have the most serverless services.
- They are rapidly innovating and offering new features.
8. Course Structure
- In Section 2 I'll introduce you to the AWS services that are absolutely required when building a serverless application.
- In Section 3 we'll cover in-depth the first two important services: Lambda and API Gateway. These allow you to set up your business logic.
- In Section 4 we'll cover how to store data using the DynamoDB AWS service.
- In Section 5 we'll cover how to have users and user authentication with the Cognito service.
- In Section 6 we'll cover how to deliver the front-end code in a serverless way using S3, CloudFront, and Route53.
- In Section 7 we'll learn about what you should learn about after you've learned what's covered in this course.
9. How to get the most out of this course
- Watch the videos. Rewatch, slow them down, repeat sections.
- Code along.
- Check the attached materials.
- Ask questions, but...
- ...also answer questions.
10. How to use the file downloads
- Not a video, just text.
- API definition files: Create a new API in API Gateway and choose "Import from Swagger".
- Before importing, replace the REGION placeholder with the region where your Lambda functions are stored, and the ACCOUNT_ID placeholder with your account id.
- AWS Lambda .zip files: Choose "Upload a .zip file" from the "Code entry type" dropdown menu.
Section 2: The Core Serverless Services
11. Module Introduction
- He recaps what he covered in Section 1: We learned what serverless development means, what AWS is, and we built a basic API.
- He gives a summary of what we'll cover in this section: we'll cover the most-core AWS services necessary for serverless development.
12. An overview of the core serverless services
- Both web apps and mobile apps will use the same back-end infrastructure, but web apps will also use additional AWS services to host the front-end code (whereas mobile apps are hosted by the Google Play Store / Apple Store), so he's going to show how to develop a web app since the mobile developers can just ignore the services they don't need.
- First we'll need to serve our static app, for example an Angular / React app. To do this we can use S3 (Simple Storage Service).
- Second we'll want to set up a REST API. To do this we can use API Gateway.
- Third we'll want to execute some code. To do this we can use Lambda.
- Fourth we'll want to store and retrieve data. To do this we can use DynamoDB. it's a NoSQL database.
- Fifth we may want to have user accounts. To do this we can use Cognito.
- Sixth, we may want to use our own URL / domain name. To do this we can use Route 53.
- Finally, we may want to use caching. To do this we can use Cloudfront.
- If you're developing a mobile app, you won't need S3, Route 53, or Cloudfront.
13. More info about the core services
- Not a video, just text.
- Links to brief Amazon overviews of the different services:
14. The course project
- The app we'll be building is called the "Compare Yourself" app.
- We will store the web app on S3.
- We will set up POST, GET, and DELETE methods for the /compare-yourself/ endpoint.
- We will also set up authentication for the app so that only registered users can access those methods.
- We will use Lambda for our business logic.
- We will store age, height, and income data in DynamoDB.
Section 3: Creating an API with API Gateway & AWS Lambda
15. Module Introduction
- He's going to start with the services which will be useful to both web and mobile developers: API Gateway, Lambda, DynamoDB, and Cognito.
16. What is API Gateway?
- How it works is:
- You'll have some kind of application: a web app, a mobile app, or something like Postman.
- That application will interact with a REST API made up of endpoints (URLs) and HTTP methods (e.g. POST), and possibly also authentication.
- This is what API Gateway does.
- That REST API will then take certain actions. API Gateway can directly access AWS services, but in particular it can run Lambda code and forward data it has received from incoming requests.
17. API Gateway: Useful resources and links
- No video, just links to official documentation:
18. Accessing the API Gateway Console
- From the AWS main page (when you're logged in), either search for "API Gateway" or look for it under "Application Services".
19. General API Gateway Features
- API keys are useful if you plan to share your API with other developers to create their own apps.
- For example, the Google Maps API.
- Go to API Keys → Actions → Create API Key.
- The user will now pass the API key with their request.
- You can also block requests that don't include an API key.
- Usage Plans is used to set "profiles" that determine how many requests certain API keys can make in a given span of time.
- Custom Domain Names allows you to connect the API to a domain that you own.
- Client Certificates is used if you want to forward requests from this API to a second API, and you want your second API to be able to verify that the requests it is receiving are coming from the first API.
- Settings is used to manage permissions. My understanding is that these are permissions for API Gateway to interact with other AWS services.
20. Understanding AWS Permissions (IAM)
- No video, just text / links.
- He links to a YouTube video he created: Account Security with IAM | Amazon Web Services BASICS
- (I've summarized it above in its own section since it's part of a series, and I want to summarize the entire series.)
- He also links to some official docs: What Is IAM?
- By default, AWS doesn't give any permissions to any of your services. That means, that no service may interact with other services.
21. API-specific Features & Options
- Remember that in the first Section, we clicked Actions → Create Resource, and then Actions → Create Method.
- In the "Resources" section of our API, we manage the resources and methods of our API.
- A "resource" is just a URL path.
- Whatever we changes we make in the Resources section are not live.
- To make our changes live, we need to select Actions → Deploy API.
- When deploying we need to choose a Stage.
- Stages are like deployed snapshots of your API.
- You can view all your stages in the "Stages" section. Basically the only thing you can do there is get the link for some particular Stage's resource.
- 'Authorizers' allows you to add authentication (logging in) to certain paths / resources.
- 'Models' allows you to specify how incoming data should be structured so that you can validate it.
- 'Documentation' is useful if you plan on sharing your API with other developers.
- 'Binary Support' is used if you plan on receiving binary data. You need to specify which filetypes should be allowed for each endpoint / method.
- 'Dashboard' gives you some logging and usage info about your API.
22. Introducing the Request-Response Cycle
- He explains the somewhat-complicated-looking diagram that shows the request-response cycle.
- 'Method Request' defines what incoming requests should look like. You can specify the format of the URL query string parameters, the HTTP request headers, and the request body. For the request body, you add a model that you define in the "Models" section.
23. Understanding the Request-Response Cycle
- 'Integration Request' is about 1) extracting / transforming the incoming request data and 2) triggering an action to take (such as a Lambda function) based on the incoming request.
- 'Integration Response' is the reverse of 'Integration Request': it allows us to configure our response. We can set headers and map content received from our action (Lambda function) to the API format.
- 'Method Response' defines the shape our response should have.
- NW: I was a bit confused about the difference between this and the Integration Response
24. Creating a New API
- So what we're going to build for this course is an API that has a single resource ("/compare-yourself") and three methods (GET, POST, DELETE).
- We'll start with the POST method.
- He clicks APIs → Create API.
- He talks about the different options.
- "New API" is what we used last time.
- "Clone from existing API" is straightfoward.
- "Import from Swagger" allows you to import a Swagger definition file. Swagger is a language that lets you define an API as a text file.
- "Example API" actually shows an example Swagger file.
- He creates a new API named 'compare-yourself'.
25. Creating a Resource( = URL Path)
- He does Actions → Create Resource.
- The new resource will be appended to whatever Resource you currently have selected. (ex: /resource-one/resource-two)
- "Configure as proxy resource" means that this will catch all other paths and methods.
- He says that one reason to use this option is that it allows you to create a full-stack app with the serverless pattern. To do it you forward all requests to a Lambda function and do the routing from within it.
- NW: I found this confusing.
- He leaves it unchecked.
- He says that one reason to use this option is that it allows you to create a full-stack app with the serverless pattern. To do it you forward all requests to a Lambda function and do the routing from within it.
26. Handling CORS and the OPTIONS Preflight Request
- CORS stands for Cross-Origin Resource Sharing.
- By default, browsers are set up to prevent the client from sending requests to a server other than the one for the website they are currently on.
- This can be a problem when you have an API which is on a different server from the one that served your HTML.
- The way around this is to have your server (NW: which one?) inform the browser via HTTP headers that making such a request is OK.
- He says that browsers will send a "pre-flight" request to your endpoint of type "OPTIONS", and in your response you need to say that CORS is OK.
- He does end up checking the box.
- His API now starts with an "OPTIONS" method.
27. Creating a (HTTP) Method
- He selects the "/compare-yourself" resource and then clicks Actions → Create Method.
- You now choose the "Integration type", which may sound strange, but it just means "What kind of action do you want to take when a request hits this method/resource?"
- "HTTP" forwards the request to another API.
- "AWS Service" forwards the request to another AWS service.
- "Lambda Function" is the one we want. It lets us run code whenever a request comes in.
- "Use Lambda Proxy Integration" will just take the incoming request data and pass it as a JSON object to the Lambda function. If you choose this, your response will not be able to use the Integration Response feature. So he opts to not use it.
- "Lambda Region" doesn't seem to matter, but he chooses to have it in the same region as the one that shows up in the top navbar.
28. What is AWS Lambda?
- AWS Lambda is a service that hosts your code and will run it when triggered by certain events.
- Examples of event sources:
- S3 - You can trigger a Lambda function when a file gets uploaded.
- CloudWatch - You can trigger a Lambda function on a schedule, like a cron job.
- API Gateway - You can trigger a Lambda function when you receive an HTTP request.
- At the time of the video, the Lambda function has to be writen in NodeJS, Python, Java, or C#.
- The Lambda function can interact with other AWS services, and can also return a response.
29. AWS Lambda: Useful Resources & Links
- No video, just text.
- AWS Lambda Pricing
30. Improved Lambda Console
- No video, just text.
- To get to the part where you can write code simply click the orange "Author from Scratch" button in the top right corner.
- Enter any role name of your choice (it'll be created automatically). If you want to use a different runtime than Node, you can change that after the function has been created.
- He strongly recommends watching this 47min talk: AWS re:Invent 2017: Authoring and Deploying Serverless Applications with AWS SAM
- He says the new editor is shown starting at 10:02.
31. Creating a Lambda Function
- You can reach the Lambda section by searching for "lambda" in the main AWS page.
- We need to choose a blueprint; let's pick the blank one.
- Next we're brought to a page to configure triggers, but we're not going to configure the connection to API Gateway here, instead we're going to do it from API Gateway. So just click 'Next' without doing anything.
- He chooses a name for his function and prepends it with an abbreviation of his project name ("cy" for "compare yourself"): "cy-store-data".
- Next he chooses a language and updates the function.
- Further down the page, you need to specify what the "main" function in the code is (what should get called).
- "context" is a function that gives you context about the request
- "callback" is a function that takes two arguments: an error argument, and the "success data"
- You need to assign a "Role" to the function.
- The function will always be given the right to create log functions.
- He skims over the "Tags" feature and the ability to set the allocated memory for the function.
- You should be careful about how much memory you allocate because you can quickly leave the free tier.
- Setting a Timeout is used to abort in case something is going wrong, to avoid unnecessary costs.
- The maximum Timeout is 5 minutes. He set the timeout for the demo function to 10 seconds.
- You can set up your function to retry if it fails ("dead-letter queue (DLQ)").
- You can also set the Lambda function to access resources within a particular Virtual Private Cloud (VPC) for security reasons.
- He disabled "Enable active tracing" because it costs extra money.
32. Lambda Pricing & Uploading Code
- No video, just text.
- For more complex code you'll probably want to bundle all your code files into a ZIP file and upload that.
- Here's how it works:
- Create a root entry file + handler method.
- You may split your code over multiple files and import them into the root file.
- Select all files and then zip them into an archive. Important: DON'T put them into a folder and zip the folder. This will not work!
33. Connecting Lambda Functions to API Gateway Endpoints
- He navigates to the "POST" method in API Gateway, goes to the "Lambda Function" textbox, starts typing out the name of the Lambda function, and it pops up as a suggestion for him to click on.
- He clicks on "Test", leaves the request body empty, and clicks "Test", and sees the "Hi, I'm Lambda!" message he set up in the Lambda function.
34. Accessing the API from the Web & Fixing CORS Issues
- He wants to test the API from an actual app.
- To make the API work outside of the API Gateway environment (i.e. on the real web), we need to deploy it (Actions → Deploy API).
- To create the demo web app he uses CodePen.io
- He sets some settings on CodePen.
- He just does an XMLHttpRequest().
Here's the code he uses:
var xhr = new XMLHttpRequest(); xhr.open('GET', 'URL-from-AWS'); xhr.onreadystatechange = function(event) { console.log(event.target.response); } xhr.send();
- When he first tries the request, it doesn't work and he gets a CORS error.
- The reason is that the POST method needs to have a header set.
- He goes to the Method Response and adds a new header that has some specific value ("Access-Control-Allow-Origin").
- He then goes to the Integration Response section and sets the value of that header to '*' (an asterisk).
- NW: I have learned from trying it myself that the asterisk must be surrounded by single quotation marks. Double quotation marks will not work.
- He then deploys over the old API.
Assignment 1: API Gateway + Lambda Basics
The assignment
Create a new API via the API Gateway Console and give it any name you like (e.g. "assignment-1")
Create two resources on that newly created API
/fetch-data
/store-data
Add Http Methods to this endpoints
/fetch-data GET Mock action
/store-data POST Lambda action
The Mock endpoint should return some dummy/ static data (Hint: You learned how to do that in the very first API we created in the first module of the course!
The Lambda action should simply execute its callback and return any data you like
Don't forget to handle CORS!
Deploy the API and call it from a simple web app (like we used before)
- My thoughts:
- Was surprised at how few issues I ran into. I only had one issue, which was that I didn't know at first that I had to surround the asterisk with single-quotes when setting the Access-Control-Allow-Origin header.
- Instructor example
- He shows a shortcut for setting the CORS header: just go to Actions → Enable CORS
35. Understanding "event" in Lambda Functions
- He simply updates his Lambda function to return the "event" object that he gets from the Integration Request. It turns out to be simply the body of the request (so, whatever he fills out in the Integration Request step).
36. Forwarding Requests with "Proxy Integration"
- In the Integration Request, if you select "Use Lambda Proxy Integration", it will send all of the request metadata along with the request body to the Lambda function.
- If you select that option and then try to have the Lambda function return it, you'll get an error, because the object doesn't fit the schema that the Integration Response requires.
- So instead you'll need to inspect the object from within the Lambda function.
37. Accessing Lambda Logs
- You can console.log() / print() the value of the event object passed into Lambda.
- To see the output of that log/print statement, you'll need to go to CloudWatch → Logs → name-of-your-lambda-function
- By looking at the full data you can see that it's not a very way to clean way to pass all the data to the Lambda function, because (for example) the body is encoded as a JSON string and will need to be decoded by your Lambda function before it can be used. I'll show you a better way in the next video.
38. Getting Started with Body Mapping Templates
- He goes to the Integration Request and unchecks "Proxy Integration".
- In "Body Mapping Templates", he selects "When there are no templates defined", adds a new Content-Type "application/json".
- He sets the template to an empty object {}, which is what gets passed on to the Lambda function.
39. Extracting Request Data with Body Mapping Templates
- If you google API Gateway Body Mapping Template you'll find some good docs from AWS on how to use it.
- You can also select the "Method Request passthrough" template option for the "Generate template" dropdown, which will show you what it would look like if you extracted all of the data from the request.
- In this case the request body will be structured as a JavaScript object rather than as a JSON string.
- He chooses to delete everything from that default template except for the line
"body-json" : $input.json('$'),- $input is a variable provided by AWS that gives access to request data.
json('$')extracts the complete request body.
- To get just a single variable from the request body, he puts the accessor after the dollar sign in the
.jsoncall, i.e..json('$.personData.age')
40. What's the Idea behind Body Mappings?
- He reiterates that the AWS docs explain how to use the Body Mappings.
- The template uses the Apache Velocity language.
- He reiterates that
$inputrefers to the request data, and$refers to the request body. - The keys you choose in the template mapping will be the properties that will be accessible in the Lambda function.
41. Understanding Body Mapping Templates
- No video, just text.
- He links to the docs for the Apache Velocity language
- He reiterates that the purpose of body mappings is "to control which data your action receives".
- He reiterates what $input and json() are.
- He points out that if the value in the JSON will be a string, you need to wrap the $input.json() call in double-quotes, whereas if it's going to be a number / boolean / object you don't wrap it in quotes. So that's like how Jinja works.
- AWS - $input variable
- AWS - API Gateway Mapping Template Reference
42. Mapping Response Data
- This is just a quick video showing that the Integration Response mapping works the same as the Integration Request mapping.
- He shows how putting empty curly braces in the Integration Response will overwrite the value returned from Lambda.
$refers to the data returned by Lambda.
43. Using Models & Validating Requests
- He wants to create a Model and use it to validate incoming data.
- He goes to Models → Create.
- He uses a model schema that is apparently following the "JSON Schema" syntax.
- After creating the model he goes to Method Request for the POST method, then to the Request Body section.
- He adds a new Content type of "application/json" and sets the "Model name" value to his new model.
- He then scrolls up and changes the "Request Validator" option to "Validate body".
44. Understanding JSON Schemas
- No video, just text.
- You can learn more about JSON Schema on the following page: http://json-schema.org/
- The best place to start learning is this page, though: https://spacetelescope.github.io/understanding-json-schema/
45. Models & Mappings
- Using Models to validate incoming requests is optional; you can do validation in Lambda instead. The benefit of using Models is that it makes it easy to return appropriate HTTP responses.
- You can also use Models in the mapping process. To do this, go to the Integration Request, scroll down to the template section, and for the "Generate template:" dropdown, you can select the model you've created.
- The template uses some syntax that might look strange:
#set($inputRoot = $input.path('$'))is setting the value of the variable $inputRoot to the request body. - He shows that the Integration Response can generate a template from the Model, just like the Integration Request.
Assignment 2 - Models and Mappings
- The assignment
- Create a new API (e.g. "assignment-2") and add a POST method to it.
- Create a Model, feel free to re-use the Schema from before. Optionally, if you feel super-confident, play around with the properties of the model and edit it.
- Use the model to validate incoming requests (request bodies) AND use it to create Body Mapping Templates for both the request and response.
- In the request Body Mapping Template you should ensure that only ONE property reaches Lambda (e.g. the income if you stick to the original model). In Lambda, use the value and return it (e.g. divide it by ten).
- In the response Body Mapping Template, you should re-construct your model (i.e. add the two properties you dropped).
- My thoughts
46. Next Steps
- He sums up what we've covered: using models to validate requests and map data.
- Next up, he's going to talk about how to have a variable in the resource (getting all users vs. a particular user) and having a DELETE method.
47. Adding a DELETE Method Endpoint to the API
- He selects the
/compare-yourselfresource and clicks Actions → Add Method → Delete. - He's just going to have a stub Lambda function for now, and we'll get it totally functional later when we learn DynamoDB.
- He just shows himself going through the steps to set up a new Lambda function and hook it up to the DELETE method.
48. Using Path Parameters
- He wants to have the
/compare-yourselfresource have a last part that can be either/allor/singledepending on whether we want all the data or only a single piece of data. - We could do this by setting up two new sub-resources but that would be "overly complicated".
- Instead what he does is create one new sub-resource named "type", where the new path is
{type} - He creates a new Lambda function.
- We are going to set up the "event" object that the Lambda function gets so that it will have a new "type" property.
- He goes to the Integration Response and uses
$input.params('type')to access the "type" variable."type": "$input.params('type')"- Remember to enclose string values in double-quotes.
49. What about Query Parameters?
- No video, just text.
- He just says "You can also extract query parameters within Body Mapping Templates".
50. Accessing the API from the Web - The Right Way
- We need to enable CORS. He just goes to Actions → Enable CORS.
- We also need to deploy the API.
- He tests the POST request and runs into a bunch of (expected) errors, which require him to do the following:
- set the content type to "application/json":
xhr.setRequestHeader('Content-Type', 'application/json');
- convert the request body from a JavaScript object to JSON:
xhr.send(JSON.stringify({age: 28, height: 72, income: 2500}));
- set the content type to "application/json":
- He then tests the DELETE method, the
/allendpoint, and the/singleendpoint.
51. Wrap Up
- He just summarizes the topics covered. You can just refer to the summaries above.
Section 4: Data Storage with DynamoDB
52. Module Introduction
- In the last section we learned how to set up an API, but it can't do that much because we don't have a database. We're going to cover that in this section.
53. What is DynamoDB?
- It's a "fully-managed NoSQL database". So you don't have to do any provisioning and there are no relations.
- NW: Reading between the lines: It seems like it's not possible with AWS to get the same kind of easy scaling up-and-down with relational databases, so if you want to use a relational database, you'll have to worry about over- or under-provisioning.
- The data format is key-value pairs.
54. AWS: DynamoDB Useful Resources & Links
- No video, just text / links.
- Amazon - Overview of DynamoDB
- Amazon - DynamoDB Developer Documentation
- Amazon - DynamoDB Pricing
55. How DynamoDB Organizes Data
- You are always required to have a unique "Partition Key" for each top-level entry in the db.
- It's called a "Partition Key" because Amazon stores the data in a bunch of solid-state drives, and those keys are used to partition the data.
- To equally distribute requests across partitions, it's better to have random partition keys.
- In DynamoDB you can have a Primary Key (with its uniqueness constraint) that is a combination of two other keys.
- For example a UserID (Partition Key) and a Timestamp (Sort Key).
- You can also set up a Global Secondary Index if you want to be able to quickly query based on another attribute.
- You can set up five of these per table.
- You can also set up a "Local Secondary Index" which is a combination of a Partition Key and another attribute.
- NW: I didn't really understand when you might want to do this.
56. NoSQL vs. SQL
- In NoSQL you have:
- No relations
- High flexibility
- Data repetition
- No integrity checks
- Easy scalability
- In SQL:
- Relations
- Limited flexibility
- No data repetition
- Integrity checks
- Harder scalability
- So basically go with NoSQL if you can, but if you have strongly-related data, you may be best off going with SQL because NoSQL can become difficult to work with in such a situation.
57. Using DynamoDB with Lambda
- DynamoDB can be an event source that triggers a Lambda function.
- DynamoDB can also be a data store that a Lambda function accesses.
Quiz 1: DynamoDB Concepts
- What kind of database is DynamoDB?
- You don't need to manage DynamoDB servers. How do you then scale the database?
- NW: One thing I don't remember being mentioned (that came up in the answer). This method of storage isn't completely hands-off; you do need to "decide how much read/write capacity (per second) you need".
- What's "Provisioned Throughput" or "Read and Write Capacity" all about?
- Answer: "It defines how many read or write actions you may perform per action." More info here.
- How do you access DynamoDB actions via Lambda?
- NW: He hadn't actually covered this before asking this question.
- What's a "Primary Key" and how is it connected to "Partition Key" and "Sort Key"
- What's the difference between scan() and getItem() ?
- NW: Pretty sure he hasn't covered this yet.
- "getItem() only returns one item, scan() returns multiple items."
58. Creating a Table in DynamoDB
- Steps for creating a table:
- Search for "dynamo" in the AWS console to find the DynamoDB section.
- Make sure your region is set correctly because that's where the DB will be.
- Click the big "Create table" button in the center of the screen.
- He chooses "compare-yourself" as the db name.
- He chooses "UserId" as the partition key, and makes it a string.
- He shows the "Secondary indexes" option.
- He says he'll talk about the "Provisioned capacity" option in the next lecture.
59. Understanding Read & Write Capacity
60. Creating and Scanning Items
61. What about multiple Databases?
62. Accessing DynamoDB from Lambda
63. Sidenote: How Lambda works behind the Scenes
64. Putting Items into a DynamoDB Table from Lambda
65. Setting Permissions Right
66. Using API Gateway (Request) Data for Item Creation
TODO: Summarize the lectures up to this one.
67. Mapping the Response & Web Testing
68. Scanning Data in DynamoDB from Lambda
69. Improving the IAM Permissions
70. Restructuring Fetched Data in Lambda
71. Getting a Single Item from DynamoDB via Lambda
72. Testing it from the Web & Passing Correct Data
73. Preparing "Delete" Permissions
74. Giving Lambda Logging Rights
75. Deleting Items in DynamoDB via Lambda
76. Mapping DynamoDB Responses
77. Wrap Up
Section 5: Authenticating Users with Cognito and API Gateway Authorizers
78. Module Introduction
79. How to add Authorization to API Gateway
80. Understanding Custom Authorizers (API Gateway)
81. Creating a Custom Authorizer Function
82. Custom Authorizers: Provided Input & Expected Output
83. MUST READ: New UI for setting up Custom Authorizers
84. Using Custom Authorizers
85. Retrieving Users from Custom Authorizers
86. What is AWS Cognito?
87. AWS Cognito: Useful Resources & Links
88. Cognito User Pools and Federated Identities
89. Creating a Cognito User Pool
90. Understanding the Cognito Auth Flow
91. The Example Web App, Angular, and TypeScript
92. Adding Cognito to a Frontend App - Getting Started
93. Using Cognito in iOS or Android Apps
94. Adding Signup to the Frontend App
95. Adding User Confirmation to a Frontend App
96. Adding Signin to a Frontend App
97. Managing User State with Cognito
98. Using a Cognito Authorizer with API Gateway
99. Passing the right User ID to Lambda
100. Using Query Params & Cognito from Lambda
101. More on the Cognito Identity Service Provier
102. Passing Query Params from the Frontend
103. Passing the User ID to the DELETE Endpoint
104. Wrap Up
Section 6: Hosting a Serverless SPA
105. Module Introduction
106. What is S3?
107. AWS S3: Useful Resources & Links
108. Creating an S3 Bucket
109. Uploading the Web App to the Bucket
110. Turning an S3 Bucket into a Static Webserver
111. Setting up Logging
112. Optimizing Content Delivery: What is AWS CloudFront?
113. AWS CloudFront: Useful Resources & Links
114. Setting up a Cloudfront Distribution
115. Finishing the CloudFront Setup
116. Using a Custom Domain: What is Route53?
117. AWS Route53: Useful Resources & Links
118. Registering a Domain
119. Connecting a Domain to a CloudFront Distribution
120. Wrap Up
Section 7: Beyond the Basics - An Outlook
121. Module Introduction
122. Documenting an API
123. Other AWS Lambda Triggers
124. Going Serverless with a Node / Express App (Non-API!)
125. Running Node / Express Apps via Lambda + API Gateway
126. Pros and Cons of Serverless + Express Apps
127. Learn more about AWS Serverless + Express Apps
128. Serverless Apps and Security
129. A Case of a Better Development Workflow
130. Getting to know the Serverless framework
131. More about the Serverless Framework
132. Getting to know SAM (Serverless Application Model) by AWS
133. More about the Serverless Application Model (SAM)
134. Testing Serverless Apps with localstack
135. Other useful AWS Services
136. Wrap Up
137. Useful Resources & Links
Section 8: Course Roundup
138. Roundup
Tutorials
- AWS - Deploying a Flask Application
- 2012.08.31 - Adam Crosby - Deploying Flask on AWS with Elastic Flask Baseline
- 2013.06.12 - tushman.io - First Impressions With Flask and Elastic Beanstalk
- 2014.04.14 - Medium - Elastic Beanstalk and Flask: Deployment Gotcha’s
- 2015.01.17 - Medium - Deploying a Flask application on AWS
- This looks like a really good tutorial.
- He covers how to set up a database.
AWS - Connecting to AWS using Putty
Transferring Files to Your Linux Instance Using the PuTTY Secure Copy Client
The PuTTY Secure Copy client (PSCP) is a command-line tool that you can use to transfer files between your Windows computer and your Linux instance. If you prefer a graphical user interface (GUI), you can use an open source GUI tool named WinSCP. For more information, see Transferring Files to Your Linux Instance Using WinSCP.
2009.11.10 - Reddit Blog - Moving to the cloud
Set up a custom domain
Using Custom Domains with Elastic Beanstalk
Namecheap - Setting up a CNAME record (use this to redirect the domain to AWS)
Deploying a Flask app on AWS EB
- Original instructions can be found here: AWS Docs - Deploying a Flask Application
- Create a new virtualenv.
- On Windows:
- Start a Cygwin window.
- Type "python34 -m virtualenv -p python34.exe /tmp/project_name/"
- This should create the new virtualenv in "C:\tmp\project_name\".
- On Windows:
- Activate the virtualenv.
- In a Windows command prompt:
- Start a regular command prompt. ("cmd").
- Type the following and hit enter:
- "C:\tmp\name_of_virtualenv_you_want_to_activate\Scripts\activate"
- Example: "C:\tmp\flaskr\Scripts\activate"
- More info:
- I was following the instructions on Amazon's tutorial page but couldn't get them to work:
Once your virtual environment is ready, start it by typing:
. /tmp/eb_flask_app/bin/activate- I found this SE post which explained how to do it: StackExchange - Issue with virtualenv - cannot activate
source is a shell command designed for users running on Linux (or any Posix, but whatever, not Windows).
On Windows, virtualenv creates a batch file, so you should run venv\Scripts\activate.bat instead (per the virtualenv documentation on the activate script).
- Note that these instructions did not work with Cygwin, but they did work when I used a regular command prompt.
- Start a regular command prompt. ("cmd").
- In a Windows PowerShell prompt:
- The same as the previous steps, except append ".ps1" to the end of the "activate" file (it's a different file created by the virtualenv developers to allow it to work with PowerShell).
- Example: "C:\tmp\flaskr\Scripts\activate.ps1"
- Source: StackExchange - virtualenv in PowerShell?
- The same as the previous steps, except append ".ps1" to the end of the "activate" file (it's a different file created by the virtualenv developers to allow it to work with PowerShell).
- In a Windows command prompt:
- Type "python" and hit enter on the regular Windows command prompt to confirm that the correct version of Python starts.
- Install Flask from within the virtualenv by typing "python34 -m pip install flask".
- Test the app.
- Make sure you're in your virtualenv.
- Switch to the directory with the flask app.
- Try running the app from the virtualenv
- Type "python app_name.py" and hit Enter.
- Go to http://127.0.0.1:5000/ and see if the app shows up.
- Create an AWS EB config file.
- Switch to a Cygwin window.
- It wasn't working for me from PowerShell...
- Type "eb init --region us-west-2".
- Get the value of the region by looking up the region for the particular availability zone that shows up in the top-right of your AWS window:
- Get the value of the region by looking up the region for the particular availability zone that shows up in the top-right of your AWS window:
- If you have existing apps, it'll prompt you to choose which one to use, or to create a new one.
- If you've created the application in the AWS EB UI (on their website), then you can just pick it and you'll be done.
- Switch to a Cygwin window.
- Create / Deploy your app to AWS.
- To create:
- In the cygwin window, type "eb create" and hit Enter to upload your code.
- To deploy:
- Same thing except type "eb deploy".
- To create:
Errors and how to deal with them
- "ERROR Your WSGIPath refers to a file that does not exist."
- http://stackoverflow.com/questions/20558747/how-to-deploy-structured-flask-app-on-aws-elastic-beanstalk
As of awsebcli 3.0, you can actually edit your configuration settings to represent your WSGI path via eb config. The config command will then pull (and open it in your default command line text editor, i.e nano) an editable config based on your current configuration settings. You'll then search for WSGI and update it's path that way. After saving the file and exiting, your WSGI path will be updated automatically.
- Basically, AWS doesn't know what the name of your main python file is.
- http://stackoverflow.com/questions/20558747/how-to-deploy-structured-flask-app-on-aws-elastic-beanstalk
Python on AWS Elastic Beanstalk - Gotchas that aren't discussed in the official docs
- This is important to read!